साइटमैप.xml और उसकी सामान्य त्रुटियाँ: लैब्रिका द्वारा विश्लेषण
एक Sitemap.xml फ़ाइल अनिवार्य रूप से आपकी वेबसाइट का एक मानचित्र है जो विशेष रूप से सर्च इंजनों द्वारा आपकी साइट के आसान नेविगेशन और इंडेक्सिंग के लिए डिज़ाइन किया गया है। यह आपके public_html फ़ोल्डर (या साइट रूट) के भीतर स्थित है और इसमें सर्च इंजन क्रॉलर्स के लिए महत्वपूर्ण निर्देश शामिल हैं जो यह निर्दिष्ट करते हैं कि कौन सी पृष्ठों पर जाना चाहिए, किस क्रम में, और कितनी बार उन पर जाना चाहिए।
यह महत्वपूर्ण पृष्ठों की इंडेक्सिंग प्रक्रिया को काफी तेज़ करता है और सर्च क्रॉलर्स को आपके और आपके उपयोगकर्ताओं दोनों के लिए उच्च महत्व के पृष्ठों पर अपना क्रॉल समय आवंटित करने की अनुमति देता है।
एक sitemap.xml बनाना हमेशा आवश्यक नहीं होता है लेकिन हमेशा अनुशंसित है, विशेष रूप से हजारों पृष्ठों वाली बड़ी साइटों के लिए। बड़ी साइटों के साथ, यह सुनिश्चित करने की आवश्यकता आती है कि सर्च इंजन क्रॉलर्स अपना समय उन उच्च मूल्य पृष्ठों पर बिताएं जिनमें गहरी सामग्री और व्यावसायिक इरादा है, न कि साइड पृष्ठ जो पतली मूल्य प्रदान करते हैं।
एक नियम के रूप में, जब सॉफ़्टवेयर और CMS’s स्वचालित रूप से एक sitemap.xml फ़ाइल उत्पन्न करते हैं, तो वे इंडेक्सिंग के लिए सभी उपलब्ध पृष्ठों को शामिल करते हैं। एक विशिष्ट वेबसाइट मालिक इसके बारे में जागरूक नहीं होने की संभावना है, और जबकि उन्होंने कुछ पृष्ठों के लिए noindex सेट किया हो सकता है, उनकी स्वचालित रूप से उत्पन्न साइटमैप इन पृष्ठों को शामिल कर रहे हैं और मूल्यवान क्रॉल बजट बर्बाद कर रहे हैं!
यह अत्यधिक अनुशंसित है कि आप विशिष्ट URLS को अपनी साइटमैप में दिखाने, कुछ URL’s को टालने, URL’s को क्रॉल करने के क्रम और उन्हें कितनी बार क्रॉल करने के लिए प्लगइन्स, कस्टम सॉफ़्टवेयर, या साइटमैप जनरेटर्स का उपयोग करें।
लैब्रिका द्वारा पाई गई साइटमैप त्रुटियाँ
ध्यान दें! साइटमैप त्रुटि रिपोर्ट केवल तभी सुलभ होगी यदि पूरी वेबसाइट को स्कैन करने के लिए पर्याप्त अनुमतियाँ सही ढंग से कॉन्फ़िगर की गई हैं। अन्यथा, लैब्रिका केवल साइटमैप.xml में विशेष रूप से सूचीबद्ध पृष्ठों को देख पाएगी बजाय वेबसाइट पर सभी पृष्ठों को देखने और फिर उन्हें साइटमैप में सूचीबद्ध पृष्ठों के साथ क्रॉस-तुलना करने में सक्षम होने के।
लैब्रिका साइटमैप विश्लेषण निम्नलिखित प्रकार की त्रुटियों को खोजने में मदद करता है:
-
पृष्ठ जो साइटमैप में मौजूद हैं लेकिन इंडेक्सिंग के लिए पहुंच योग्य नहीं हैं।
-
पृष्ठ जो साइटमैप में मौजूद हैं लेकिन noindex टैग है।
-
पृष्ठ जो साइटमैप में मौजूद नहीं हैं लेकिन इंडेक्सेबल हैं।
कृपया ध्यान दें: विभिन्न सर्च इंजन साइटमैप नियमों को अलग-अलग तरीकों से प्रोसेस करते हैं। Google, सबसे अधिक बार, केवल उन पृष्ठों को इंडेक्स करेगा जो स्वचालित क्रॉलिंग के माध्यम से पहुंच योग्य हैं बिना साइटमैप के। यानी, पृष्ठ जो उस दिन आपकी साइट के लिए आवंटित क्रॉल समय और क्रॉल गहराई के भीतर आंतरिक लिंक के माध्यम से पहुंच योग्य हैं। वे आपके sitemap.xml फ़ाइल को यह पता लगाने के लिए नहीं देखेंगे कि कौन से लिंक क्रॉल करने हैं, बल्कि साइटमैप को साइटमैप में सूचीबद्ध पृष्ठों को कितनी बार क्रॉल करने के लिए गाइड के रूप में उपयोग करेंगे।
पृष्ठ साइटमैप में मौजूद है, लेकिन इंडेक्सिंग के लिए पहुंच योग्य नहीं है
यह रिपोर्ट मुख्य रूप से ऑर्फन पृष्ठों को हाइलाइट करती है, जो अनिवार्य रूप से पृष्ठ हैं जो आपकी साइट पर मौजूद हैं लेकिन उन पर कोई इनबाउंड लिंक नहीं है और वे ‘मालिकहीन’ हैं।
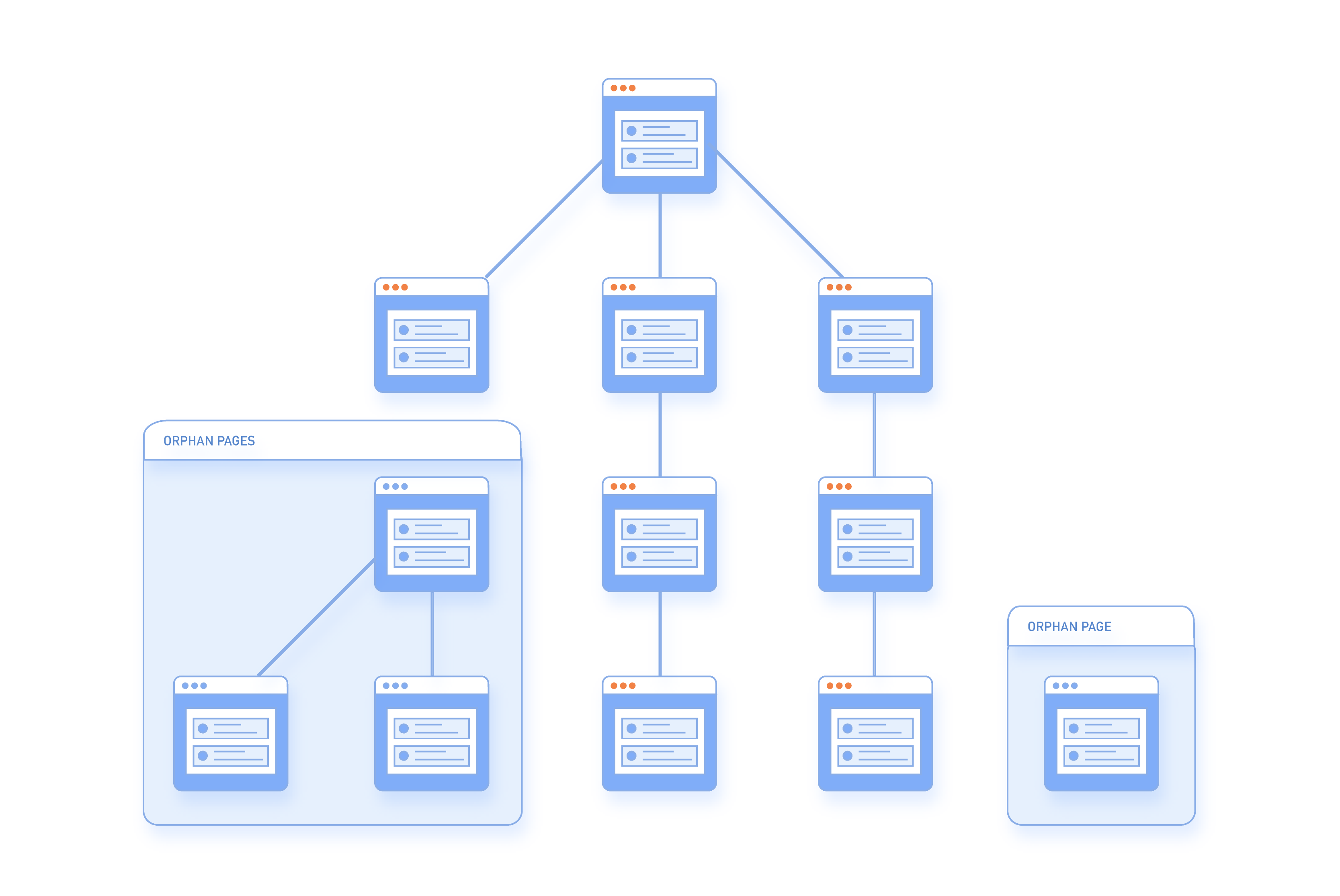
यदि ऐसे पृष्ठ किसी तरह सर्च इंजनों द्वारा इंडेक्स किए जाते हैं, तो वे शून्य PageRank होने की संभावना रखते हैं और अच्छी रैंकिंग नहीं करेंगे। यह ऑनलाइन अच्छी तरह से प्रलेखित है कि Google और अन्य बड़े सर्च इंजन पृष्ठों की SEO शक्ति और मूल्य को निर्धारित करने के लिए PageRank स्कोर (और इसके विभिन्न रूप) का उपयोग करते हैं। यह सिर्फ कुछ साल पहले था कि Google ने आपको एक टूलबार का उपयोग करने की अनुमति दी थी जो आपके पृष्ठों का PageRank दिखाता था, लेकिन दुर्भाग्य से, यह सार्वजनिक क्षेत्र से हटा दिया गया था। प्राकृतिक रूप से, आप अपने विभिन्न पृष्ठों के लिए अच्छा PageRank चाहते हैं, इसलिए यदि आपका कोई लैंडिंग पेज इस त्रुटि श्रेणी में समाप्त हो जाता है (यानी, आपका पृष्ठ सिर्फ एक ऑर्फन पेज नहीं है) तो आप समस्या के स्रोत पर तुरंत पहुंचना चाहेंगे।
आपके पृष्ठ को साइटमैप में मौजूद होने लेकिन इंडेक्सिंग के लिए पहुंच योग्य नहीं होने के सामान्य कारण:
-
एक noindex टैग किए गए पृष्ठ/पृष्ठों से एक लिंक इस पृष्ठ की ओर जाता है, या इस पृष्ठ की ओर जाने वाले पृष्ठ प्रतिक्रियाशील नहीं हैं। परिणामस्वरूप, सर्च इंजन क्रॉलर आगे या पीछे नहीं जा सकता, और इसलिए सत्र समाप्त कर देता है।
-
आवश्यक पृष्ठों के लिए लिंक अवरुद्ध हैं। उदाहरण के लिए, rel="nofollow" विशेषता के माध्यम से। यानी, क्रॉलर पृष्ठ के लिंक को देखता है, लेकिन यह निषिद्ध होने के कारण उस पर नेविगेट नहीं कर सकता।
-
इस पृष्ठ के लिए कोई लिंक नहीं है और यह सच में ‘अनाथ’ है।
-
पृष्ठ वेबसाइट संपादक/CMS में हटा दिया गया था लेकिन HTML फ़ाइल अभी भी साइट पर जीवित है।
-
पृष्ठ साइटमैप में मौजूद है लेकिन क्रॉलेबल नहीं है, इसलिए इंडेक्स नहीं किया जा सकता।
इस प्रकार की त्रुटि को सबसे अच्छी तरह से निम्नलिखित करके सुधारा जाता है;
जांचें कि कौन से पृष्ठ noindex और nofollow टैग हैं और उन्हें सुधारें और/या सुनिश्चित करें कि पृष्ठ को सही क्रॉलिंग को सक्षम करने के लिए प्राथमिक मेनू में सही ढंग से जोड़ा गया है। साथ ही, अधिकांश समय, हम इस प्रकार की त्रुटि को व्यावसायिक और सूचनात्मक साइटों के साथ देखते हैं जो पेजिनेशन को ब्लॉक करती हैं।
समस्या को कैसे ठीक करें?
जब एक पृष्ठ साइटमैप में उपलब्ध है लेकिन साइट पर किसी अन्य पृष्ठ से कोई आंतरिक लिंक नहीं है तो इसे ऑर्फन पेज के रूप में जाना जाता है।
ऑर्फन पृष्ठ SEO के लिए खराब हैं क्योंकि वे कोई लिंक वेट नहीं ले जाते और इसलिए सर्च इंजनों द्वारा महत्वहीन माने जाते हैं। उन्हें पहले ब्लैक हैट SEO में भी इस्तेमाल किया गया था।
एक बार हमारे डैशबोर्ड में पहचाने जाने पर आप कर सकते हैं:
- यदि पृष्ठ उपयोगी है, कीवर्ड के लिए रैंक करता है, या बाहरी साइटों से बैकलिंक हैं, तो पृष्ठ को अपनी साइट लिंकिंग स्कीम में पुनः एकीकृत करें।
- यदि साइट पर पहले से ही लिंक किया गया एक निकट डुप्लिकेट पृष्ठ है तो पृष्ठ को दूसरे के साथ मिलाएं।
- यदि इसका कोई उपयोग नहीं है तो पृष्ठ को पूरी तरह से हटा दें। या 404, या 410 (समाप्त सामग्री) कोड वापस करें।
- उत्पाद पृष्ठों के लिए जहां आइटम समाप्त हो सकता है आप समान श्रेणी में नए उत्पादों से लिंक कर सकते हैं, पृष्ठ को एक नए लीड स्रोत बनाते हुए। (यह वही है जो eBay समाप्त नीलामी लिस्टिंग के साथ करता है)। अधिक ट्रैफ़िक उत्पन्न करने में मदद करता है।
पृष्ठ साइटमैप में मौजूद है लेकिन noindex टैग है
ये वे पृष्ठ हैं जिन्हें एक noindex टैग का उपयोग करके इंडेक्सिंग से मना किया गया है लेकिन अभी भी साइटमैप में कहीं मौजूद हैं।
लोग विभिन्न कारणों से पृष्ठों को noindex करते हैं लेकिन साइटमैप में noindex पृष्ठों को सूचीबद्ध करना गोपनीय डेटा के लीक होने का कारण बन सकता है लेकिन सबसे अधिक संभावना, यह क्रॉलर्स को अपना समय और क्रॉल बजट बर्बाद करने का कारण बनता है।
इस समस्या को ठीक करने के लिए आपको बस साइटमैप से noindex पृष्ठ/पृष्ठों को हटाना होगा ताकि कोई भी सर्च इंजन गलती से एक पृष्ठ को इंडेक्स न करे जो वे नहीं करना चाहिए (हालांकि वे आमतौर पर noindex टैग का पालन करते हैं)।
समस्या को कैसे ठीक करें?
यह आमतौर पर तब होता है जब एक पृष्ठ को rel="nofollow" विशेषता के माध्यम से इंडेक्सिंग से ब्लॉक किया गया है।
इन पृष्ठों को साइटमैप में शामिल करना उपयोगी नहीं है क्योंकि यह क्रॉल बजट का उपयोग करता है और संभावित रूप से गोपनीय जानकारी के लीक की ओर ले सकता है। इसे ठीक करने के लिए आप बस अपने साइटमैप से पृष्ठ को हटा सकते हैं।
लैब्रिका का त्रुटि मुक्त sitemap.xml फ़ाइल डाउनलोड करें
ऊपर सूचीबद्ध विभिन्न साइटमैप त्रुटि रिपोर्टों में से प्रत्येक के लिए, लैब्रिका आपको अपने sitemap.xml फ़ाइल का एक त्रुटि मुक्त और सुधारा संस्करण डाउनलोड करने की क्षमता प्रदान करती है। यह आपको अपने sitemap.xml फ़ाइल को मैन्युअल रूप से सुधारने में समय बचाएगा, और सबसे महत्वपूर्ण, अपने सर्च इंजन क्रॉल बजट का बेहतर उपयोग करेगा।
