इंडेक्सिंग क्या है और पेजों को इंडेक्स से कैसे ब्लॉक करें
इंडेक्सिंग क्या है?
इंडेक्सिंग साइट पेजों का विश्लेषण करने की प्रक्रिया है (यह आमतौर पर सर्च इंजनों द्वारा किया जाता है) और फिर क्रॉल करने के बाद, उन्हें सर्च इंजन इंडेक्स में जोड़ना। इस इंडेक्स (डेटाबेस) का उपयोग सर्च परिणाम बनाने के लिए किया जाता है, और साथ ही सर्च परिणामों के भीतर पेजों की रैंकिंग (अल्गोरिदम द्वारा क्वेरी इंटेंट संतुष्टि और सफल SEO के आधार पर पेजों का आगे विश्लेषण करने के बाद)। इंडेक्सिंग एक क्रॉलर/सर्च इंजन रोबोट द्वारा की जाती है।
हमें सर्च इंजन इंडेक्स से जानकारी को बाहर करने की क्षमता क्यों चाहिए?
एक नियम के रूप में, जानकारी जो सर्च परिणामों में प्रदर्शित नहीं होनी चाहिए, उसे “noindex” टैग का उपयोग करके या साइट के कुछ अनुभागों/पेजों के क्रॉलिंग को robots.txt फाइल में ब्लॉक करके सर्च इंजन इंडेक्स से ब्लॉक किया जा सकता है।
पेज जो आमतौर पर सर्च इंजनों से ब्लॉक किए जाते हैं, वे तकनीकी, मालिकाना और गोपनीय प्रकृति के होते हैं, और उन्हें सर्च परिणामों में रखने के लिए अनुपयुक्त माना जाता है।
एक व्यावसायिक साइट के भीतर इसका उदाहरण; उपयोगकर्ताओं के खातों, शॉपिंग कार्ट, उत्पाद तुलना, डुप्लिकेट पेज, साइट के भीतर सर्च परिणाम इत्यादि की ओर इशारा करने वाले लिंक हो सकते हैं!
ये पेज ग्राहकों के लिए मूल्यवान हैं और साइट की कार्यक्षमता के लिए आवश्यक हैं, लेकिन सर्च इंजन इंडेक्स के लिए उपयोगी नहीं हैं।
सर्च इंजनों द्वारा पेजों को इंडेक्स करने से ब्लॉक करने के तरीके
पेजों की इंडेक्सिंग को रोकने के कई तरीके हैं:
-
robots.txt फाइल का उपयोग करना।
Robots.txt एक टेक्स्ट फाइल है जो सर्च इंजनों को बताती है कि कौन से पेज इंडेक्स किए जा सकते हैं और कौन से पेज इंडेक्स नहीं किए जा सकते।
robots.txt में एक पेज को इंडेक्स करने से ब्लॉक करने के लिए, आपको Disallow निर्देश का उपयोग करना होगा।
robots.txt फाइल का उदाहरण जो कैटलॉग पेजों की इंडेक्सिंग की अनुमति देता है जबकि कार्ट की इंडेक्सिंग को अस्वीकार करता है:
# साइट के रूट डायरेक्टरी में robots.txt फाइल की सामग्री, # जो '/catalog' से शुरू होने वाली पेजों और फाइलों की इंडेक्सिंग को सक्षम करती है Allow: /catalog # '/cart' से शुरू होने वाली पेजों और फाइलों की इंडेक्सिंग को ब्लॉक करें Disallow: /cart
-
<meta> robots टैग का उपयोग noindex विशेषता के साथ।
इस विशेषता का उपयोग करके एक पेज को ब्लॉक करने के लिए, आपको पेज के
<head>अनुभाग में निम्नलिखित लाइनें जोड़नी होंगी:पूरे पेज को इंडेक्सिंग से ब्लॉक करने के लिए आपको पेज के
<head>ब्लॉक में निम्नलिखित लाइन रखनी चाहिए:<meta name="robots" content="noindex">
-
लिंक को nofollow करना ताकि वे उस पेज को इंडेक्स न करें जिसकी ओर वे लिंक कर रहे हैं।
इसे करने के दो तरीके हैं:
-
लिंक द्वारा लिंक आधार पर क्रॉलर को ब्लॉक करना:
<a href="/page" rel="nofollow"> लिंक टेक्स्ट </a>
ध्यान रखें कि यह विधि केवल तभी काम करेगी जब पेज के लिए हर एक लिंक में “nofollow” विशेषता हो। यदि एक लिंक में यह विशेषता गायब है तो सर्च इंजन क्रॉलर उसे फॉलो करेगा और पेज अभी भी इंडेक्स किया जाएगा।
-
पेज को स्वयं nofollow विशेषता देकर पेज पर किसी भी लिंक को फॉलो करने से क्रॉलर को ब्लॉक करना:
पेज के
<head>ब्लॉक में नीचे दी गई लाइन जोड़कर, क्रॉलर को पेज को फॉलो करने से ब्लॉक किया जाएगा और इसलिए पेज के भीतर निहित कोई भी लिंक इंडेक्स नहीं किया जाएगा।<meta name="robots" content="nofollow" />
-
-
आप HTML पेज के हेडर में किसी विशिष्ट सर्च इंजन द्वारा पेज को क्रॉल किए जाने से भी ब्लॉक कर सकते हैं, उदाहरण के लिए:
आप इस लाइन को पेज के
<head>ब्लॉक में रख सकते हैं; यह पेज को Google द्वारा इंडेक्स किए जाने से ब्लॉक करेगा (क्योंकि आपने उनके क्रॉलर को पूरी तरह से ब्लॉक कर दिया है):<meta name="googlebot" content="noindex">
आप एक विशिष्ट पेज को “noindex” करने का विकल्प भी चुन सकते हैं जबकि Google को उस पेज पर लिंक को फॉलो करने की अनुमति देते हैं, और फिर “noindex” पेज से लिंक किए गए पेजों को इंडेक्स करें:
<meta name="googlebot" content="noindex, follow">
-
Canonical पेज।
rel=canonical विशेषता का उपयोग सर्च इंजन को इंगित करने के लिए किया जाता है कि पेज एक canonical पेज है (सबसे अधिक अधिकारपूर्ण एक)। यह क्रॉलर को इंगित करता है कि यह इंडेक्स करने के लिए पसंदीदा पेज है और उनकी साइट पर इस सामग्री का सबसे अधिकारपूर्ण उदाहरण है।
Canonical पेजों को निर्दिष्ट करना आवश्यक है ताकि एक ही सामग्री वाले पेज इंडेक्स न हों जो फिर SERP में पेज की रैंकिंग को नुकसान पहुंचा सकते हैं।
आप इस विशेषता का उपयोग तब करेंगे जब आपके पास एक ही सामग्री वाले कई पेज हों लेकिन विभिन्न डिवाइसों के लिए अलग-अलग URL हों:
https://example.com/news/https://m.example.com/news/https://amp.example.com/news/
या जब पेज के लिए कई ‘sort’ विकल्प उपलब्ध हों जो पेज URL को बदल देंगे लेकिन एक ही सामग्री दिखाएंगे:
https://example.com/catalog/https://example.com/catalog?sort=datehttps://example.com/catalog?sort=cost
या यदि लिंक URL के भीतर दिए गए उत्पाद के विभिन्न आकारों को निर्दिष्ट करता है:
https://example.com/catalog/shirthttps://example.com/catalog/shirt?size=XLhttps://example.com/catalog/shirt38
rel=canonical विशेषता निम्नानुसार लागू की जाती है:
<link rel=canonical href="https://example.com/catalog/shirt" />
नोट: आपको इस विशेषता को पेज के
<head>ब्लॉक में रखना चाहिएHTTP अनुरोध के हेडर में वांछित canonical पेज दर्ज करना भी संभव है।
हालांकि, सावधान रहें क्योंकि आपके ब्राउज़र के लिए विशेष प्लगइन्स के उपयोग के बिना, आप यह नहीं पता लगा सकते कि यह विशेषता सही ढंग से सेट की गई है क्योंकि अधिकांश ब्राउज़र अपने उपयोगकर्ताओं को HTTP हेडर नहीं दिखाते।
HTTP / 1.1 200 OK Link: <https://example.com/catalog/shirt>; rel=canonical
आप Google दस्तावेज़ीकरण में canonical पेजों के बारे में और पढ़ सकते हैं।
-
एक विशिष्ट URL के लिए "X-Robots-Tag" HTTP अनुरोध हेडर का उपयोग करना:
HTTP / 1.1 200 OK X-Robots-Tag: google: noindex
सावधान रहें क्योंकि आपके ब्राउज़र के लिए विशेष प्लगइन्स के उपयोग के बिना, आप यह नहीं पता लगा सकते कि यह विशेषता सही ढंग से सेट की गई है क्योंकि अधिकांश ब्राउज़र अपने उपयोगकर्ताओं को HTTP हेडर नहीं दिखाते।
मैं अपनी साइट पर इंडेक्सिंग से ब्लॉक किए गए पेज कैसे ढूंढ सकता हूं?
आप इस जानकारी को अपने Labrika डैशबोर्ड के "SEO audit" - "Pages blocked from indexing" अनुभाग में देख सकते हैं।
रिपोर्ट पेज पर आप परिणामों को फ़िल्टर कर सकते हैं ताकि कोई भी लैंडिंग पेज देख सकें जो इंडेक्सिंग से ब्लॉक किए गए हैं। ऐसा करने के लिए आपको “critical error” बटन पर क्लिक करना होगा।
आमतौर पर, जब एक सर्च इंजन क्रॉलर आपकी साइट पर आता है, तो यह आंतरिक लिंकों के माध्यम से सभी पेजों को क्रॉल करेगा जो वह पा सकता है और फिर उन्हें तदनुसार इंडेक्स करेगा।
इस रिपोर्ट का उद्देश्य उन पेजों को दिखाना है जो इंडेक्स किए जाने से ब्लॉक किए गए हैं। ये आमतौर पर ऐसे पेज होते हैं जिनमें टॉप 50 सर्च परिणामों में कोई कीवर्ड नहीं होते, और हो सकता है कि आपने उन्हें जानबूझकर सर्च इंजनों से इंडेक्सिंग से ब्लॉक कर दिया हो।
Labrika’s “Pages blocked from indexing” report
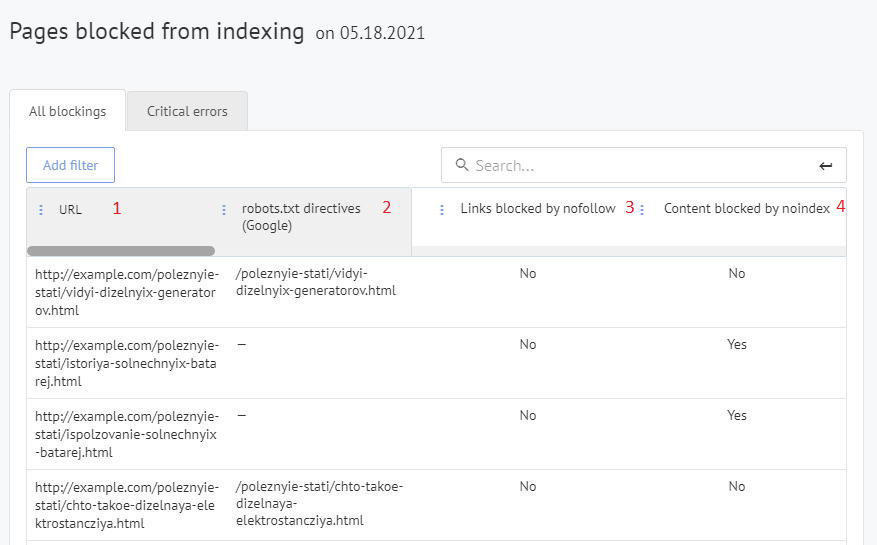
- किसी भी पेज के URL जो वर्तमान में इंडेक्सिंग से ब्लॉक हैं।
- robots.txt में वह निर्देश जो इस पेज के लिए इंडेक्सिंग को ब्लॉक कर रहा है (यदि पेज को इस विधि द्वारा Google में इंडेक्सिंग से ब्लॉक किया गया है)।
- क्या इस पेज को nofollow विशेषता के माध्यम से ब्लॉक किया गया है।
मैं इस रिपोर्ट में शामिल एक पेज को noindexed से कैसे रोक सकता हूं?
कई आधुनिक कंटेंट मैनेजमेंट सिस्टम (CMS) में, आप robots.txt फाइल, rel= canonical, "robots" meta tag, “noindex”, और “nofollow” विशेषताओं को बदल सकते हैं। इसलिए, इस रिपोर्ट में शामिल एक पेज को फिर से इंडेक्स करने योग्य बनाने के लिए, आपको केवल उस विशेषता/टैग को हटाना होगा जो इस पेज को इंडेक्स नहीं करने का कारण बना रहा है। ऐसा करने के लिए कई सरल प्लगइन्स हैं जो आपको ऐसा करने की अनुमति देते हैं। यदि आप इसे स्वयं बदल नहीं सकते तो इसे एक डेवलपर को आउटसोर्स करना एक अपेक्षाकृत सरल कार्य होगा।